Kinematic Self-Replicating Machines
© 2004 Robert A. Freitas Jr. and Ralph C. Merkle. All Rights Reserved.
Robert A. Freitas Jr., Ralph C. Merkle, Kinematic Self-Replicating Machines, Landes Bioscience, Georgetown, TX, 2004.
5.10 Replicators and Artificial Intelligence (AI)
The possible creation of a machine-based human-equivalent or human-different artificial intelligence (AI) – whether deliberately built or emergent – has been described in the technical scientific [912, 2872-2884], popular scientific [2886-2891], and science fiction [2892-2898] literatures for many decades. True human-equivalent computing is conservatively estimated to require a computational capacity on the order of 10-1000 teraflops (~1013-1015 floating-point operations/sec) [2884-2887], though various estimation methods can produce a somewhat wider range of values (1012-1017 ops/sec) [2887, 2912-2914]. (IBM’s ~1012 ops/sec Deep Blue parallel computer defeated human grandmaster Gary Kasparov at chess in 1997 [2870].) These bit rates are many orders of magnitude higher than the data processing requirements of all classes of contemporary industrial manufacturing machines, and also well beyond most estimates of the computational capacities needed to drive future autonomous nanorobotic devices. For example, artificial nanorobotic red cells (respirocytes [229]) may require no more than a simple ~103 ops/sec computer – far less computing power than an old Apple II machine – while nanorobotic white cells (microbivores [233]) may need only ~106 ops/sec of onboard capacity. Still more sophisticated cellular repair nanorobots should demand no more than 106-109 ops/sec of onboard computing capacity to do their work (Nanomedicine [228], Section 7.1), a full 4-9 orders of magnitude below the estimates for true human-equivalent computing.
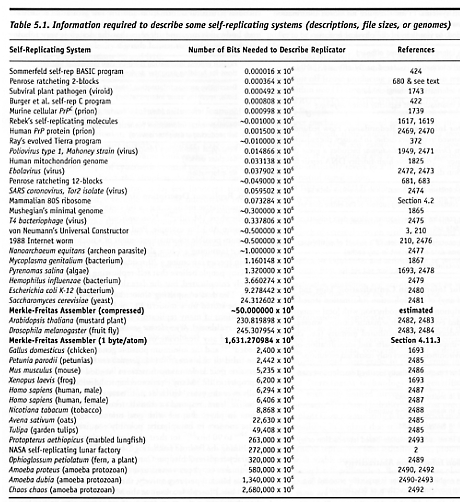
Similarly, estimates of the data storage capacity of the human brain have ranged from a low of ~200 megabytes (1.6 x 109 bits) for consciously-recoverable data [2915], to a range of 1013-1015 bits based on an assumption of ~1 bit per synapse [2885, 2916, 2917], to upper limits of 2.2 x 1018 bits for the information contained in a lifetime of experience (brain inputs) [2885, 2913, 2918] or 1020 bits based on the accumulated total of all neural impulses conducted within the brain during a lifetime [2919]. (One recent estimate [2920] of 108432 bits for total human memory seems wildly implausible.) By contrast, Table 5.1 shows that a wide variety of mechanical, software, and biological replicators require at most 102-1012 bits for the storage of their description, and the actual number is likely to be considerably less. For example, the self-replicating DNA sequence that describes the human phenotype is nominally 6 x 109 bits [2487], but there is a great amount of repetition (such as the 300,000 “ALU” sequence repeats) so the data may compressible by at least 100:1 if the noncoding regions are greatly condensed or eliminated, reducing the bit count to under ~108 bits – or 2-12 orders of magnitude smaller than the storage capacity required to store a human-level intelligence. The number of data bits needed to support an artificial intelligence seems to be many orders of magnitude larger than the number of bits that are likely required to support an artificial replicator.
In the 1970s, Carl Sagan [2921] quoted AI expert Marvin Minsky as claiming that as few as 106 bits might be enough to encode an artificially-designed “true intellect” – provided the bits “were all in the right place....I cannot conceive that it would take 1012 bits to hold a superintelligent being.”* (The 2003 release of Microsoft Windows requires ~2.4 x 1010 bits of storage – 50 million lines of code averaging 60 characters/line at 8 bits per character.) By comparison, the simplest-known software replicators require only 16-808 bits to encode (depending on one’s definitions; Section 2.2.1 and Table 5.1), so it would seem that replicators may be at least 3-5 orders of magnitude simpler than intelligences, even if Minsky is correct.
* Minsky does not recall making this exact claim [2922] and believes the original quotation came from a book written by Minsky in 1968 [2923], containing the following paragraph: “As one tries to classify all of one’s knowledge, the categories grow rapidly at first, but after a while one encounters more and more difficulty. My impression, for what it is worth, is that one can find fewer than ten areas, each with more than ten thousand such links. Nor can one find a hundred things that one knows a thousand things about, or a thousand things, with a hundred such links. I therefore feel that a machine will quite critically need to acquire the order of a hundred thousand elements of knowledge in order to behave with reasonable sensibility in ordinary situations. A million, if properly organized, should be enough for a very great intelligence. If my argument does not convince you, multiply the figures by ten.”
From the more recent work done on large commonsense knowledge bases, Douglas Lenat’s “CYC” Project and Push Singh’s “OpenMind Commonsense” Project each have on the order of a million entries, and Minsky [2922] suspects “that each would need to be at least 10 times larger to ‘know’ as much as a not-very-well-informed person. So this suggests that a person might need between 10 and 100 millions of ‘knowledge units’ whatever these are.” Positing that each ‘element of knowledge’ (with several ‘links’) would need on the order of a few hundred bits, Minsky [2922] estimates that “if we had to convert this to ‘bits’, that might come to the order of a few hundred megabytes. If this is right, then your mind might fit nicely onto a present day 700 MB CD-ROM. Another argument which favors this order of magnitude: psychologists have never found situations in which a person can store in long-term memory more than one or two ‘items’ per second. This suggests an upper bound of the order of 10 million units per year.”
In other words, replication appears to be a rather simple activity when compared to intelligence. We conclude that artificial replicators are likely to require many orders of magnitude less memory and data processing capacity than an artificial intelligence, hence are unlikely to incorporate an onboard artificial intelligence unless the inclusion of an AI is a principal design objective. Indeed, common computer viruses and worms are examples of artificial software replicators (Section 2.2.1) and are typically small in size (a few kilobytes). Adding an AI to a replicator would greatly increase the complexity and design difficulty of building a replicator, and would also increase the risks to public safety (Section 5.11). If emergent AIs prove easier to create than deliberately-built AIs, e.g., by using genetic algorithms, then the risk to public safety is again increased [2898]. Non-AI replicators are vastly simpler to design and build (and will be much safer to operate) than artificial intelligence based replicators. As technology progresses, it is likely that basic multifunctional replicators can be built long before an AI can be built, and that at least the earliest generations of artificial replicators will contain no onboard AI. Our conclusion is supported by the observation that in the evolution of life on Earth, the first replicators may have appeared only ~0.8 billion years [2924, 2925] after the planet’s formation but another 3.5-3.85 billion years [2924-2926] of further evolution were required for human-level intelligence to emerge [2927], employing the same organic substrate.
Last updated on 1 August 2005
{kind=link}