
Kinematic Self-Replicating Machines
© 2004 Robert A. Freitas Jr. and Ralph C. Merkle. All Rights Reserved.
Robert A. Freitas Jr., Ralph C. Merkle, Kinematic Self-Replicating Machines, Landes Bioscience, Georgetown, TX, 2004.
5.9.6 Design Tradeoffs in Nanofactory Assembly Process Specialization
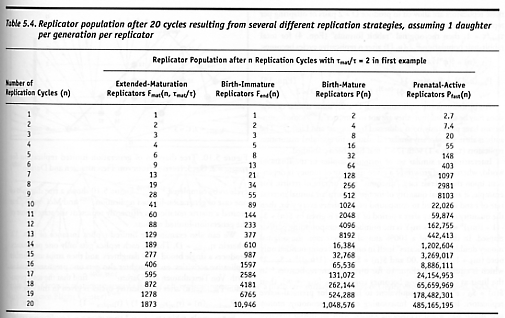
The specialization of active subunit components within a replicator system seems likely to increase manufacturing throughput rates as compared to systems having only general-purpose active subunits, though probably at the cost of reduced flexibility [208]. As we saw in Section 5.9.2, allowing increasing numbers of active subcomponents to contribute immediately to replication processes improves the growth rate from P(t) = 2t/t (Eqn. 10B) to a maximum of Pfast(t) = et/t (Eqn. 11B). In effect, the division of a single general-purpose replicator working mass of a particular type into the maximum possible number of more-specialized working sub-masses of the same particular type increases replicator productivity by up to a factor of (e1/21) = 1.359 per generation in the limit, an amount that grows to a (e20/220) = 463 fold advantage in the limit by the 20th generation (Table 5.4), a substantial improvement. This assumes that a significant amount of total manufacturing time is utilized in increasing the total manufacturing capacity, rather than in making nonreplicating (non-self) product outputs.
Another estimate, inspired by an analysis by Hall [225] but using more conservative assumptions, can compare the benefits of specialization using replicating systems having components of two different particular types – for example, mill-type mechanisms and manipulator-type mechanisms. As noted earlier (Section 5.1.9 (H6)), with one set of assumptions, specialized mill-type mechanisms may be ~40 times more productive per unit mass than manipulator-type mechanisms, although manipulator systems are far more versatile or “general purpose” than mill systems. So it is logical to presume that a replicating system composed entirely of mill-type mechanisms, using similar assumptions, should be ~40 times more productive per unit mass than a replicating system composed entirely of manipulator-type mechanisms.
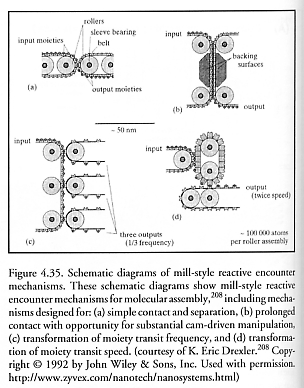
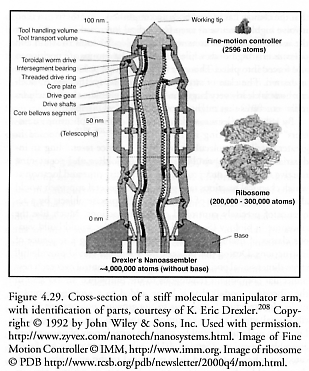
Accordingly, let us consider two possible self-replicating systems, one that is “specialized” and another that is “general-purpose.” The specialized factory consists of molecular mills (Figure 4.35) that may include separate assembly lines specialized for gears, pulleys, shafts, bearings, motors, struts, pipes, self-fastening joints, and so forth. Its architecture also includes conveyors and a tiny number of general-purpose manipulators for putting the final parts together (which are few enough that we can ignore them in the calculation). The general-purpose factory consists exclusively of some number of general-purpose programmable robotic arm manipulators of the kind described by Drexler (Figure 4.29), with no specialized molecular mills included. We will estimate the time tmacro required for each system to grow large enough to be capable of producing macroscale products, a capacity threshold which Hall [225] arbitrarily defined as the ability to do Rmacro = 1020 mechanosynthetic atom-deposition reactions per second (~0.5 mm3/sec of solid diamond crystal), starting from a much smaller initial seed system.
Consider first the specialized replicating system of molecular mills. If:
then the productivity of all specialized mill mechanisms is RmillS = nparttypes · NPARTSa · Vconveyor / xstation (atoms/sec), the number of individual mill mechanisms per part type in the initial seed system is nmills = NPARTSa / natomM, and the replication time of the initial seed system is tmillS = q · (nmills · NMILLa / NPARTSa) / (Vconveyor / xstation), hence the time required for the specialized system to grow to macroscale capacity is tmacroS = tmillS · GmillS (generations) where GmillS = log10(Rmacro / RmillS) / log10(2), or:
and the total number of atoms in the initial seed system is:
Taking q = 2 (Hall [225]), natomM ~ 1 atom/mill (Nanosystems [208], Section 13.2.3; Hall [225]), NMILLa = 2.5 x 105 atoms/mill mechanism (Nanosystems [208], Section 13.3.5.c), xstation = 10 nm (Nanosystems [208], Section 13.3.1.a; Hall [225]), NPARTSa = 104 atoms/part (Hall [225]), Vconveyor = 0.005 m/sec (Nanosystems [208], Section 13.3.1.a), Rmacro = 1020 atoms/sec (Hall [225]), and nparttypes = 100 (Hall [225]), then RmillS = 5 x 1011 atoms/sec, nmills = 104 mills/part type, tmillS = 1 sec and NseedSa = 5 x 1011 atoms in the initial seed system, with tmacroS = 28 seconds to replicate GmillS = 28 doubling generations of the initial seed system to reach the threshold of macroscale manufacturing output.
Consider next the general-purpose replicating system of manipulator arms. If:

then the number of individual arm mechanisms in the initial seed system is narms = NseedGa / NARMa, the productivity of all general-purpose manipulator arm mechanisms in the seed system is RarmG = narms / (tmotion · nmotion ) (atoms/sec), and the replication time of the initial seed system is tarmG = q · NseedGa / RarmG, hence the time required for the specialized system to grow to macroscale capacity is tmacroG = tarmG · GarmG (generations) where GarmG = log10(Rmacro / RarmG) / log10(2), or:
Taking q = 2 (Hall [225]), NARMa = 107 atoms/arm (Nanosystems [208], Section 13.4.1.f; Hall [225]), tmotion = 10-6 sec per 10-nm motion (Nanosystems [208], Section 13.4.1.f), nmotion = 2 motions per atom deposition (one motion from tool recharge to workpiece plus one motion from workpiece to tool recharge), Rmacro = 1020 atoms/sec (Hall [225]), and NseedGa = NseedSa = 5 x 1011 atoms (to permit easy comparison with a mill-based system of exactly equal size), then narms = 5 x 104 manipulator arms, RarmG = 2.5 x 1010 atoms/sec, and tarmG = 40 sec in the initial seed system, with tmacroG = 1276 seconds to replicate GarmG = 32 doubling generations of the initial seed system to reach the threshold of macroscale manufacturing output. (Note also that NARMa / NMILLa = 40.)
Thus, as expected, the specialized system can replicate tarmG / tmillS = 40 times faster* than the comparably-sized general-purpose system and also allows faster build-out (e.g., tmacroG / tmacroS = 46) and higher throughput rates (e.g., RmillS / RarmG = 20), but at the cost of losing virtually all programmable variation in the building blocks and block assemblies which are exclusively assembled by mill mechanisms. It should be easier to have newly manufactured subcomponents contributing immediately in a nanofactory consisting of robot arms since each arm could be set to work on whatever job was to be done next, while a newly-built special-purpose mill would have to wait for its companion mills to be finished (and connected together) before it could start making products.
* These results are largely insensitive to the exact choice of Rmacro and nparttypes but are highly sensitive to the choice of Vconveyor, NPARTSa and tmotion. Drexler suggests that specialized mills and general-purpose manipulators might even have comparable replication times for some choices of parameters, e.g., t ~ 3 sec for mills (Nanosystems [208], Section 13.3.5.d) and t ~ 5 sec for manipulators (Nanosystems [208], Section 13.4.1.f). There are additional limits to convergent assembly processes based on power and heat generation, and different types of defect mechanisms at different scales [208]. A more comprehensive analysis should be performed but is beyond the scope of this book.
Adds Drexler [208]: “Manipulator-style mechanisms will tend to have lower stiffness and hence higher error rates than those of mill-style mechanisms. Nonetheless, the feasible stiffness permits errors stemming from thermal excitation to be kept to negligible levels. Manipulators under programmable control can more easily be designed for fault tolerance than can mill systems.” Functionally-specialized systems also have the potential drawback of requiring separate design, construction, and testing for each of two or more specialized machines (even if individually less complex), rather than just one general-purpose machine, and are almost certainly more constrained in the range of different products they can produce (compared to a single more general-purpose assembler).
Analogously in the field of pure computation, the GRAPE computer family (with its specialized hardware chips for efficiently calculating Newtonian gravitational force between particles in computational astrophysics [2869]) and IBM’s Deep Blue chess-playing computer (with its specialized chess-move calculation hardware chips [2870]) have shown greater speed at one narrow task but have far less versatility* than a more general-purpose parallel computer with comparable gross hardware specifications. There is evidence that flexible “reconfigurable computing” [2871] may be superior to fixed-path hardware in many applications (e.g., see the “Embryonics project” in Section 2.2.1). In the field of manufacturing, automakers in Detroit and elsewhere have steadily moved away from single-process manufacturing on their automobile assembly lines, in favor of flexible manufacturing systems (using manufacturing robots more akin to manipulators than to mills) that allow different products to be produced on the same production line and that also allow rapid switching between products.
* The implications of using manufacturing components functionally analogous to the reconfigurable logic as found in Field-Programmable Gate Array (FPGA) technology should be investigated further in the context of flexible nanomanufacturing and specialization.
Finally, readers are reminded that there are many ways to operationalize component and active subunit specialization. One way is via a “factory production line” approach with specialized sub-lines, as in Drexler’s desktop assembler (Section 4.9.3) or Hall’s factory replication architecture (Section 4.16). Another way is by using specialized individual replicator devices, as in Freitas’ biphase assembler (Section 4.18). Both approaches reap the benefits of process specialization while employing utterly different architectures. Also, when discussing “production lines” vs. “replicators” it is important to clearly distinguish the concept of component function specialization (i.e., “Replication Process Specialization” or dimension “I5” in the replicator design space described in Section 5.1.9) from other temptingly-similar and seemingly-related dimensions in the replicator design space with which I5 is frequently confused or conflated, such as Replication Process Centralization (I4), Replication Process Subunit Assistance (I8), Replication Auxeticity (I11), and Replication Process Parallelicity (I13).
Last updated on 1 August 2005
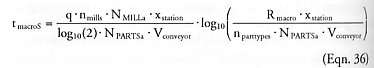
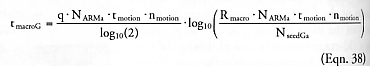
{kind=link}
{kind=link}
{kind=link}